|
-
Why can't I
just ask for the first three rows
in a table? --Because in relational
databases, rows are inserted in
no particular order, that is,
the system inserts them in an
arbitrary order; so, you can only
request rows using valid SQL features,
like ORDER BY, etc.
-
What is this
DDL and DML I hear about? --DDL
(Data Definition Language) refers
to (in SQL) the Create Table statement...DML
(Data Manipulation Language) refers
to the Select, Update, Insert,
and Delete statements. Also,
QML, referring to Select statements,
stands for Query Manipulation
Language.
-
Aren't database
tables just files? --Well, DBMS's
store data in files declared by
system managers before new tables
are created (on large systems),
but the system stores the data
in a special format, and may spread
data from one table over several
files. In the database world,
a set of files created for a database
is called a tablespace.
In general, on small systems,
everything about a database (definitions
and all table data) is kept in
one file.
-
(Related question)
Aren't database tables just like
spreadsheets? --No, for two reasons.
First, spreadsheets can have data
in a cell, but a cell is more
than just a row-column-intersection.
Depending on your spreadsheet
software, a cell might also contain
formulas and formatting, which
database tables cannot have (currently).
Secondly, spreadsheet cells are
often dependent on the data in
other cells. In databases, "cells"
are independent, except that columns
are logically related (hopefully;
together a row of columns describe
an entity), and, other than primary
key and foreign key constraints,
each row in a table is independent
from one another.
-
How do I import
a text file of data into a database?
--Well, you can't do it directly...you
must use a utility, such as Oracle's
SQL*Loader, or write a program
to load the data into the database.
A program to do this would simply
go through each record of a text
file, break it up into columns,
and do an Insert into the database.
-
What web sites
and computer books would you recommend
for more information about SQL
and databases? --First, look at
the sites at the bottom of this
page. I would especially suggest
the following: Ask
the SQL Pro (self-explanatory),
DB Ingredients
(more theorical topics), DBMS Lab/Links (comprehensive
academic DBMS link listing), Access on the
Web (about web access of Access
databases), Tutorial
Page (listing of other tutorials),
and miniSQL
(more information about the best
known free DBMS).
-
What is a schema?
--A schema is a logical set of
tables, such as the Antiques database
above...usually, it is thought
of as simply "the database", but
a database can hold more than
one schema. For example, a star
schema is a set of tables
where one large, central table
holds all of the important information,
and is linked, via foreign keys,
to dimension tables which
hold detail information, and can
be used in a join to create detailed
reports.
-
I understand
that Oracle offers a special keyword,
Decode, that allows for some "if-then"
logic. How does that work? --
Technically, Decode allows for
conditional output based on the
value of a column or function.
The syntax looks like this (from
the Oracle: Complete Reference
series):
Select ...DECODE
(Value, If1, Then1, [If 2, Then
2, ...,] Else) ...From ...;
The Value is
the name of a column, or a function
(conceivably based on a column
or columns), and for each If included
in the statement, the corresponding
Then clause is the output if the
condition is true. If none of
the conditions are true, then
the Else value is output. Let's
look at an example:
Select Distinct
City,
DECODE (City, 'Cincinnati',
'Queen City', 'New York', 'Big
Apple', 'Chicago',
'City of Broad Shoulders',
City) AS Nickname
From Cities;
The output might
look like this:
City
Nickname
------------ ------------------------------
Boston
Boston
Cincinnati Queen
City
Cleveland
Cleveland
New York
Big Apple
'City' in the
first argument denotes the column
name used for the test. The second,
fourth, etc. arguments are the
individual equality tests (taken
in the orden given) against each
value in the City column. The
third, fifth, etc. arguments are
the corresponding outputs if the
corresponding test is true. The
final parameter is the default
output if none of the tests are
true; in this case, just print
out the column value.
TIP: If you want
nothing to be output for a given
condition, such as the default
"Else" value, enter the value
Null for that value, such as:
Select Distinct
City,
DECODE (City, 'Cincinnati',
'Queen City', 'New York', 'Big
Apple', 'Chicago',
'City of Broad Shoulders',
Null) AS Nickname
From Cities;
If the City column
value is not one of the ones mentioned,
nothing is outputted, rather than
the city name itself.
City
Nickname
------------ ----------
Boston
Cincinnati Queen
City
Cleveland
New York
Big Apple
-
You mentioned
Referential Integrity before,
but what does that have to do
with this concept I've heard about,
Cascading Updates and Deletes?
--This is a difficult topic to
talk about, because it's covered
differently in different DBMS's.
For example,
Microsoft SQL Server (7.0 &
below) requires that you write
"triggers" (see the Yahoo SQL
Club link to find links that discuss
this topic--I may include that
topic in a future version of this
page) to implement this. (A quick
definition, though; a Trigger
is a SQL statement stored in the
database that allows you to perform
a given query [usually an "Action"
Query--Delete, Insert, Update]
automatically, when a specified
event occurs in the database,
such as a column update, but anyway...)
Microsoft Access (believe it or
not) will perform this if you
define it in the Relationships
screen, but it will still burden
you with a prompt. Oracle does
this automatically, if you specify
a special "Constraint" (see reference
at bottom for definition, not
syntax) on the keyed column.
So, I'll just
discuss the concept. First, see
the discussion above on Primary
and Foreign keys.
Concept: If a
row from the primary key column
is deleted/updated, if "Cascading"
is activated, the value of the
foreign key in those other tables
will be deleted (the whole row)/updated.
The reverse,
a foreign key deletion/update
causing a primary key value to
be deleted/changed, may or may
not occur: the constraint or trigger
may not be defined, a "one-to-many"
relationship may exist, the update
might be to another existing primary
key value, or the DBMS itself
may or may not have rules governing
this. As usual, see your DBMS's
documentation.
For example,
if you set up the AntiqueOwners
table to have a Primary Key, OwnerID,
and you set up the database to
delete rows on the Foreign Key,
SellerID, in the Antiques table,
on a primary key deletion, then
if you deleted the AntiqueOwners
row with OwnerID of '01', then
the rows in Antiques, with the
Item values, Bed, Cabinet, and
Jewelry Box ('01' sold them),
will all be deleted. Of course,
assuming the proper DB definition,
if you just updated '01' to another
value, those Seller ID values
would be updated to that new value
too.
-
Show me an
example of an outer join.
--Well, from the questions I receive,
this is an extremely common example,
and I'll show you both the Oracle
and Access queries...
Think of the
following Employee table (the
employees are given numbers, for
simplicity):
| Name |
Department |
| 1 |
10 |
| 2 |
10 |
| 3 |
20 |
| 4 |
30 |
| 5 |
30 |
Now think of
a department table:
Now suppose you
want to join the tables, seeing
all of the employees and all of
the departments together...you'll
have to use an outer join which
includes a null employee to go
with Dept. 40.
In the book,
"Oracle 7: the Complete Reference",
about outer joins, "think of the
(+), which must immediately follow
the join column of the table,
as saying add an extra (null)
row anytime there's no match".
So, in Oracle, try this query
(the + goes on Employee, which
adds the null row on no match):
Select E.Name,
D.Department
From Department D, Employee
E
Where E.Department(+) = D.Department;
This is a left
(outer) join, in Access:
SELECT DISTINCTROW
Employee.Name, Department.Department
FROM Department LEFT JOIN
Employee ON Department.Department
= Employee.Department;
And you get this
result:
| Name |
Department |
| 1 |
10 |
| 2 |
10 |
| 3 |
20 |
| 4 |
30 |
| 5 |
30 |
| |
40 |
-
What are some
general tips you would give to
make my SQL queries and databases
better and faster ( optimized)?
- You should try, if you
can, to avoid expressions
in Selects, such as SELECT
ColumnA + ColumnB, etc. The
query optimizer of
the database, the portion
of the DBMS that determines
the best way to get the required
data out of the database itself,
handles expressions in such
a way that would normally
require more time to retrieve
the data than if columns were
normally selected, and the
expression itself handled
programmatically.
- Minimize the number of columns
included in a Group By clause.
- If you are using a join,
try to have the columns joined
on (from both tables) indexed.
- When in doubt, index.
- Unless doing multiple counts
or a complex query, use COUNT(*)
(the number of rows generated
by the query) rather than
COUNT(Column_Name).
-
What is normalization?
--Normalization is a technique
of database design that suggests
that certain criteria be used
when constructing a table layout
(deciding what columns each table
will have, and creating the key
structure), where the idea is
to eliminate redundancy of non-key
data across tables. Normalization
is usually referred to in terms
of forms, and I will introduce
only the first three, even though
it is somewhat common to use other,
more advanced forms (fourth, fifth,
Boyce-Codd; see documentation).
First Normal
Form refers to moving data
into separate tables where the
data in each table is of a similar
type, and by giving each table
a primary key.
Putting data
in Second Normal Form involves
removing to other tables data
that is only dependent of a part
of the key. For example, if I
had left the names of the Antique
Owners in the items table, that
would not be in Second Normal
Form because that data would be
redundant; the name would be repeated
for each item owned; as such,
the names were placed in their
own table. The names themselves
don't have anything to do with
the items, only the identities
of the buyers and sellers.
Third Normal
Form involves getting rid
of anything in the tables that
doesn't depend solely on the primary
key. Only include information
that is dependent on the key,
and move off data to other tables
that are independent of the primary
key, and create a primary key
for the new tables.
There is some
redundancy to each form, and if
data is in 3NF (shorthand
for 3rd normal form), it is already
in 1NF and 2NF.
In terms of data design then,
arrange data so that any non-primary
key columns are dependent only
on the whole primary key.
If you take a look at the sample
database, you will see that the
way then to navigate through the
database is through joins using
common key columns.
Two other important
points in database design are
using good, consistent, logical,
full-word names for the tables
and columns, and the use of full
words in the database itself.
On the last point, my database
is lacking, as I use numeric codes
for identification. It is usually
best, if possible, to come up
with keys that are, by themselves,
self-explanatory; for example,
a better key would be the first
four letters of the last name
and first initial of the owner,
like JONEB for Bill Jones (or
for tiebreaking purposes, add
numbers to the end to differentiate
two or more people with similar
names, so you could try JONEB1,
JONEB2, etc.).
-
What is the
difference between a single-row
query and a multiple-row
query and why is it important
to know the difference? --First,
to cover the obvious, a single-row
query is a query that returns
one row as its result, and a multiple-row
query is a query that returns
more than one row as its result.
Whether a query returns one row
or more than one row is entirely
dependent on the design (or schema)
of the tables of the database.
As query-writer, you must be aware
of the schema, be sure to include
enough conditions, and structure
your SQL statement properly, so
that you will get the desired
result (either one row or multiple
rows). For example, if you wanted
to be sure that a query of the
AntiqueOwners table returned only
one row, consider an equal condition
of the primary key column, OwnerID.
Three reasons
immediately come to mind as to
why this is important. First,
getting multiple rows when you
were expecting only one, or vice-versa,
may mean that the query is erroneous,
that the database is incomplete,
or simply, you learned something
new about your data. Second, if
you are using an update or delete
statement, you had better be sure
that the statement that you write
performs the operation on the
desired row (or rows)...or else,
you might be deleting or updating
more rows than you intend. Third,
any queries written in Embedded
SQL must be carefully thought
out as to the number of rows returned.
If you write a single-row query,
only one SQL statement may need
to be performed to complete the
programming logic required. If
your query, on the other hand,
returns multiple rows, you will
have to use the Fetch statement,
and quite probably, some sort
of looping structure in your program
will be required to iterate processing
on each returned row of the query.
-
Tell me about
a simple approach to relational
database design. -- First, create
a list of important things (entities)
and include those things you may
not initially believe is important.
Second, draw a line between any
two entities that have any connection
whatsoever; except that no two
entities can connect without a
'rule'; e.g.: families have children,
employees work for a department.
Therefore put the 'connection'
in a diamond, the 'entities' in
squares. Third, your picture should
now have many squares (entities)
connected to other entities through
diamonds (a square enclosing an
entity, with a line to a diamond
describing the relationship, and
then another line to the other
entity). Fourth, put descriptors
on each square and each diamond,
such as customer -- airline --
trip. Fifth, give each diamond
and square any attributes it may
have (a person has a name, an
invoice has a number), but some
relationships have none (a parent
just owns a child). Sixth, everything
on your page that has attributes
is now a table, whenever two entities
have a relationship where the
relationship has no attributes,
there is merely a foreign key
between the tables. Seventh, in
general you want to make tables
not repeat data. So, if a customer
has a name and several addresses,
you can see that for every address
of a customer, there will be repeated
the customer's first name, last
name, etc. So, record Name in
one table, and put all his addresses
in another. Eighth, each row (record)
should be unique from every other
one; Mr. Freedman suggests a 'auto-increment
number' primary key, where a new,
unique number is generated for
each new inserted row. Ninth,
a key is any way to uniquely identify
a row in a table...first and last
name together are good as a 'composite'
key. That's the technique.
-
What are relationships?
--Another design question...the
term "relationships" (often termed
"relation") usually refers to
the relationships among primary
and foreign keys between tables.
This concept is important because
when the tables of a relational
database are designed, these relationships
must be defined because they determine
which columns are or are not primary
or foreign keys. You may have
heard of an Entity-Relationship
Diagram, which is a graphical
view of tables in a database schema,
with lines connecting related
columns across tables. See the
sample diagram at the end of this
section or some of the sites below
in regard to this topic, as there
are many different ways of drawing
E-R diagrams. But first, let's
look at each kind of relationship...
A One-to-one
relationship means that you
have a primary key column that
is related to a foreign key column,
and that for every primary key
value, there is one foreign
key value. For example, in the
first example, the EmployeeAddressTable,
we add an EmployeeIDNo column.
Then, the EmployeeAddressTable
is related to the EmployeeStatisticsTable
(second example table) by means
of that EmployeeIDNo. Specifically,
each employee in the EmployeeAddressTable
has statistics (one row
of data) in the EmployeeStatisticsTable.
Even though this is a contrived
example, this is a "1-1" relationship.
Also notice the "has" in bold...when
expressing a relationship, it
is important to describe the relationship
with a verb.
The other two
kinds of relationships may or
may not use logical primary key
and foreign key constraints...it
is strictly a call of the designer.
The first of these is the one-to-many
relationship ("1-M"). This
means that for every column value
in one table, there is one
or more related values in
another table. Key constraints
may be added to the design, or
possibly just the use of some
sort of identifier column may
be used to establish the relationship.
An example would be that for every
OwnerID in the AntiqueOwners table,
there are one or more (zero is
permissible too) Items bought
in the Antiques table (verb: buy).
Finally, the
many-to-many relationship
("M-M") does not involve keys
generally, and usually involves
idenifying columns. The unusual
occurence of a "M-M" means that
one column in one table is related
to another column in another table,
and for every value of one of
these two columns, there are one
or more related values in the
corresponding column in the other
table (and vice-versa), or more
a common possibility, two tables
have a 1-M relationship to each
other (two relationships, one
1-M going each way). A [bad] example
of the more common situation would
be if you had a job assignment
database, where one table held
one row for each employee and
a job assignment, and another
table held one row for each job
with one of the assigned employees.
Here, you would have multiple
rows for each employee in the
first table, one for each job
assignment, and multiple rows
for each job in the second table,
one for each employee assigned
to the project. These tables have
a M-M: each employee in the first
table has many job assignments
from the second table, and each
job has many employees
assigned to it from the first
table. This is the tip of the
iceberg on this topic...see the
links below for more information
and see the diagram below for
a simplified example of
an E-R diagram.
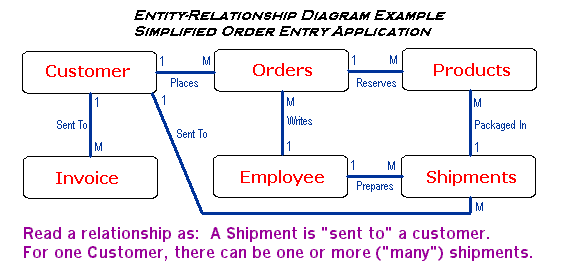
-
What are some
important nonstandard SQL features
(extremely common question)? --Well,
see the next section...
|
|
| |
|
| |
| |
|
